Bert介绍!💐
Bert介绍
1.模型结构
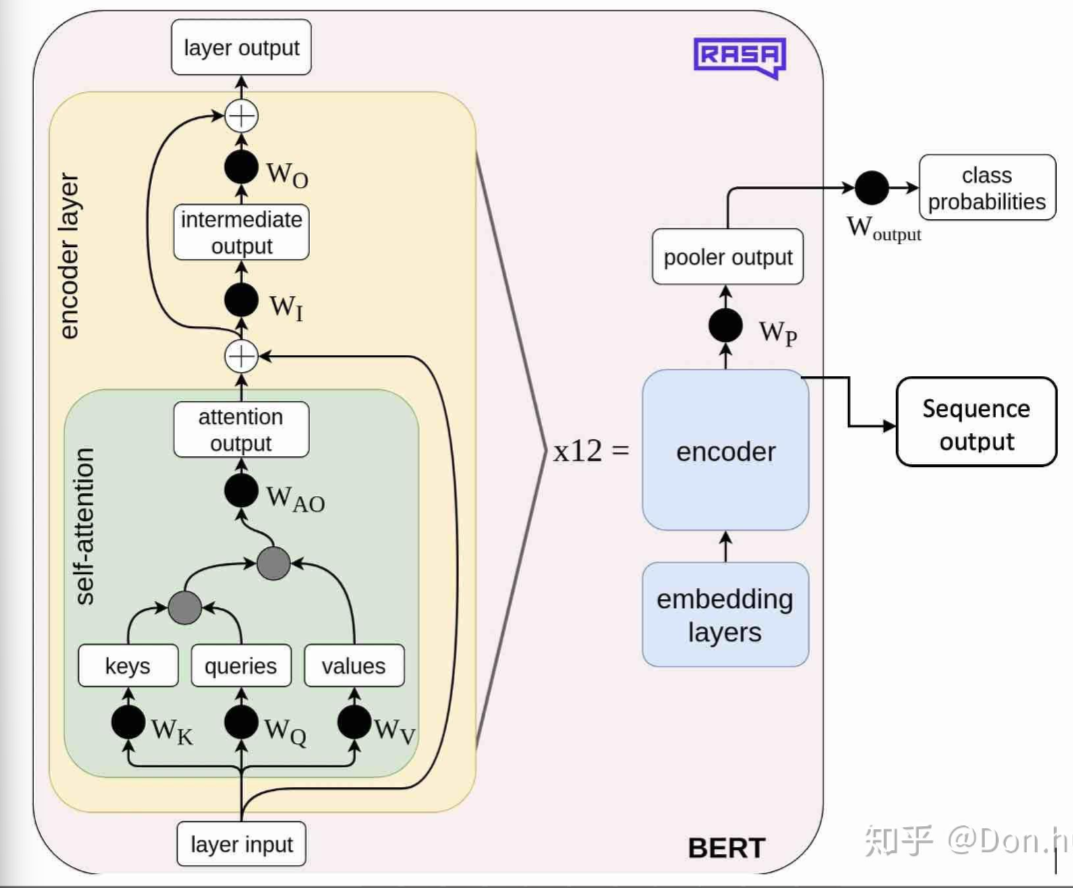
模型可以简单的归纳为三个部分,分别是输入层,中间层,以及输出层。这些都和transformer的encoder一致,除了输入层有略微变化。
1.1 输入层
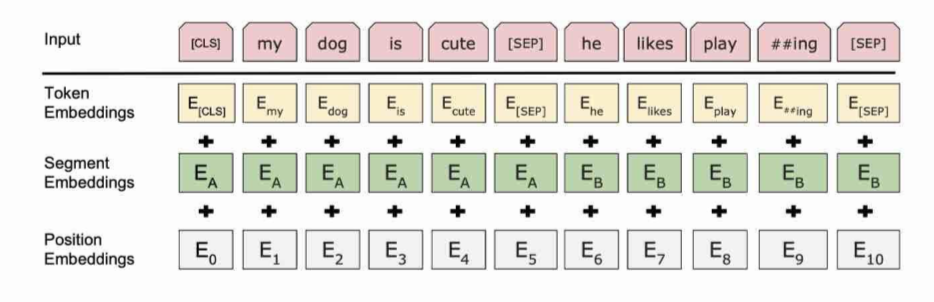
为了使得BERT模型适应下游的任务(比如说分类任务,以及句子关系QA的任务),输入将被改造成[CLS]+句子A(+[SEP]+句子B+[SEP]) 其中
- [CLS]: 代表的是分类任务的特殊token,它的输出就是模型的pooler output
- [SEP]:分隔符
- 句子A以及句子B是模型的输入文本,其中句子B可以为空,则输入变为[CLS]+句子A
因为trasnformer无法获得字的位置信息,BERT和transformer一样也加入了 绝对位置 position encoding,但是和transformer不同的是,BERT使用的是不是transformer对应的函数型(functional)的encoding方式,而是直接采用类似word embedding的方式(Parametric),直接获得position embedding。
因为我们对输入进行了改造,使得模型可能有多个句子Segment的输入,所以我们也需要加入segment的embedding,例如[CLS], A_1, A_2, A_3,[SEP], B_1, B_2, B_3, [SEP] 对应的segment的输入是[0,0,0,0,0,1,1,1,1], 然后在根据segment id进行embedding_lookup得到segment embedding。 code snippet如下。
1 | |
1.2 中间层
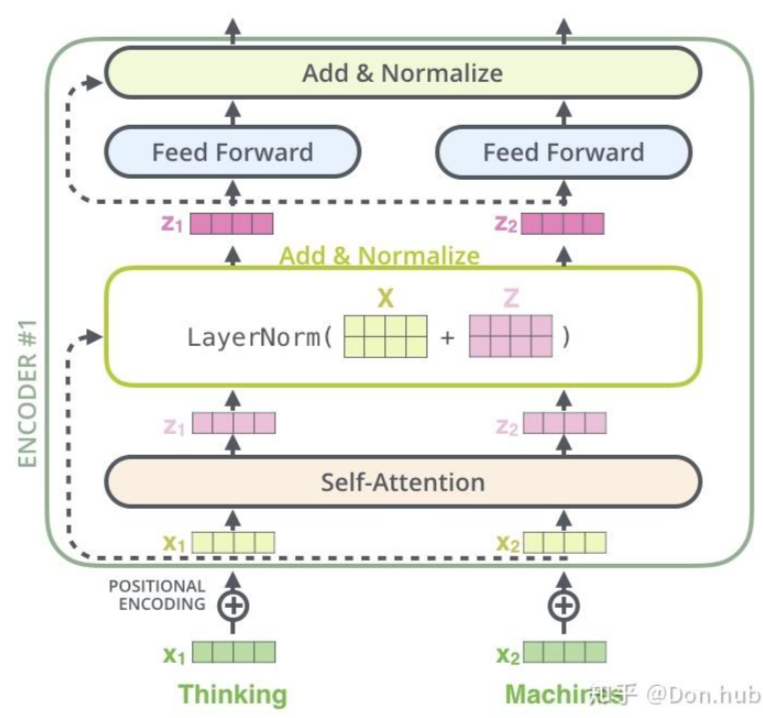
模型的中间层和transformer的encoder一样,都是由self-attention layer + ADD&BatchNorm layer + FFN 层组成的。
1.3 输出层
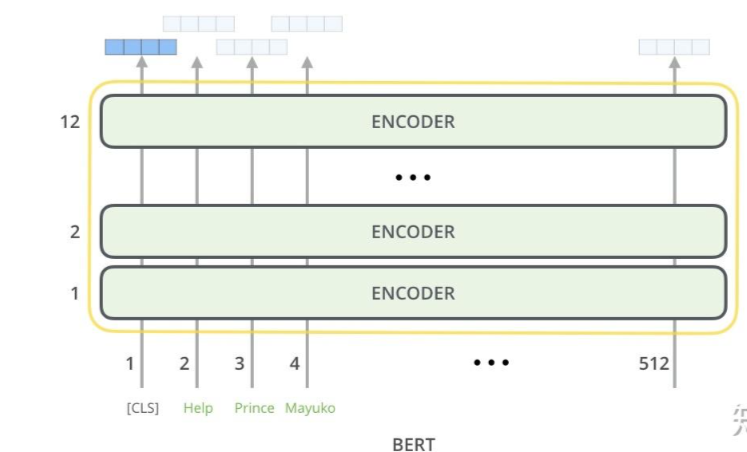
模型的每一个输入都对应这一个输出,根据不同的任务我们可以选择不同的输出,主要有两类输出
- pooler output:对应的是[CLS]的输出。
- sequence output:对应的是所有其他的输入字的最后输出。
2.模型框架
BERT提出的是一个框架,主要由两个阶段组成。分别是Pre-training以及Fine-Tuning。
2.1 预训练
2.1.1 MLM
BERT第一次采用了mask language model(MLM)任务,这就类似于完形填空(Cloze task)。
具体的做法: 我们会随机mask输入的几个词,然后预测这个词。但是这样子做的坏处是因为fine-tuning阶段中并没有[MASK] token,所以导致了pre-training 和 fine-tuning的不匹配的情况。所以为了减轻这个问题,文章中采用的做法是:对于要MASK 15%的tokens,
- (1) 80%的情况是替换成[MASK]
- (2) 10%的情况是替换为随机的token
- (3) 10%的情况是保持不变 具体的code snippet如下。
1 | |
2.1.2 NSP
为了适配下游任务,使得模型懂得句子之间的关系,BERT加了一个新的训练任务,预测两个句子是不是下一句的关系。
具体来说:50%的概率,句子A和句子B是来自同一个文档的上下句,标记为is_random_next=False, 50%的概率,句子A和句子B不是同一个文档的上下句,具体的做法就是,采用从其他的文档(document)中,加入新的连续句子(segments)作为句子B。具体参考create_instances_from_document函数。
首先我们会有一个all_documents存储所有的documents,每个documents是由句子segemnts组成的,每个segment是由单个token组成的。我们首先初始化一个chunk数组,每次都往chunk中添加同一个document中的一个句子,当chunk的长度大于target的长度(此处target的长度一般是max_seq_length,但是为了匹配下游任务,target的长度可以设置一定比例short_seq_prob的长度少于max_seq_length)的时候,随机选择一个某个句子作为分割点,前面的作为句子A,后面的作为句子B。 chunk = [Sentence1, Sentence2,…, SentenceN], 我们随机选择选择一个句子作为句子A的结尾,例如2作为句子结尾,则句子A为=[Sentence1, Sentence2]。我们有50%的几率选择剩下的句子[Sentence3,…SentenceN]作为句子B,或者50%的几率时的句子B是从其他文档中的另外多个句子。
这时候可能会导致我们的训练样本的总长度len(input_ids)大于或者小于我们的需要的训练样本长度max_seq_length。
- 如果
len(input_ids) > max_seq_length, 具体的做法是分别删除比较长的一个句子中的头(50%)或尾(50%)的token
1 | |
- 如果
len(input_ids) < max_seq_length, 采用的做法是补0。
1 | |
根据我们的两个任务,我们预训练模型的输入主要由以下7个特征组成。
input_ids: 输入的token对应的idinput_mask: 输入的mask,1代表是正常输入,0代表的是padding的输入segment_ids: 输入的0:代表句子A或者padding句子,1代表句子Bmasked_lm_positions:我们mask的token的位置masked_lm_ids:我们mask的token的对应idmasked_lm_weights:我们mask的token的权重,1代表是真实mask的,0代表的是padding的masknext_sentence_labels:句子A和B是否是上下句
2.2 微调
在Fine-Tuning阶段的时候,我们可以简单的plugin任务特定的输入和输出,作为训练。 例如:
- 2句子 pairs: 相似度任务,
- 假设-前提 pairs: 推理任务,
- 问题-文章 pairs : QA任务
- text−∅ pair: 文本分类 or 序列标注.
[CLS] representation 被喂到 最后一层作为classification的结果例如 推理任务或者 情感分析任务。
在这个任务中,就不需要MLM任务以及NSP任务所需要的输入了,所以就只有固定输入features(input_ids, input_mask, segment_ids)以及任务特定features
例如分类任务的输入特征:
input_ids: 输入的token对应的idinput_mask: 输入的mask,1代表是正常输入,0代表的是padding的输入segment_ids: 输入的0:代表句子A或者padding句子,1代表句子Blabel_ids:输入的样本的label