word2vec介绍!💐
word2vec介绍
1.词向量
词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量就是把一个词表示成一个向量。 我们都知道词在送到神经网络训练之前需要将其编码成数值变量,常见的编码方式有两种:One-Hot Representation 和 Distributed Representation。
1.1 One-Hot编码
One-Hot编码 ,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量中只有一个 1 , 其他全为 0 ,1 的位置对应该词在词典中的位置。
举个例子:I like writing code,那么转换成独热编码就是:
**I **1 0 0 0 like 0 1 0 0 writing 0 0 1 0 code 0 0 0 1
缺点:
1.容易受维数灾难的困扰,尤其是将其用于 Deep Learning的一些算法时
2.词汇鸿沟,不能很好地刻画词与词之间的相似性
3.强稀疏性
1.2 Distributed编码
其基本想法是:通过训练将某种语言中的每一个词 映射成一个固定长度的短向量(当然这里的“短”是相对于One-Hot Representation的“长”而言的),所有这些向量构成一个词向量空间,而每一个向量则可视为 该空间中的一个点,在这个空间上引入“距离”,就可以根据词之间的距离来判断它们之间的语法、语义上的相似性了。
2.Word2Vec的网络结构
Word2Vec是轻量级的神经网络,其模型仅仅包括输入层、隐藏层和输出层,模型框架根据输入输出的不同,主要包括CBOW和Skip-gram模型。
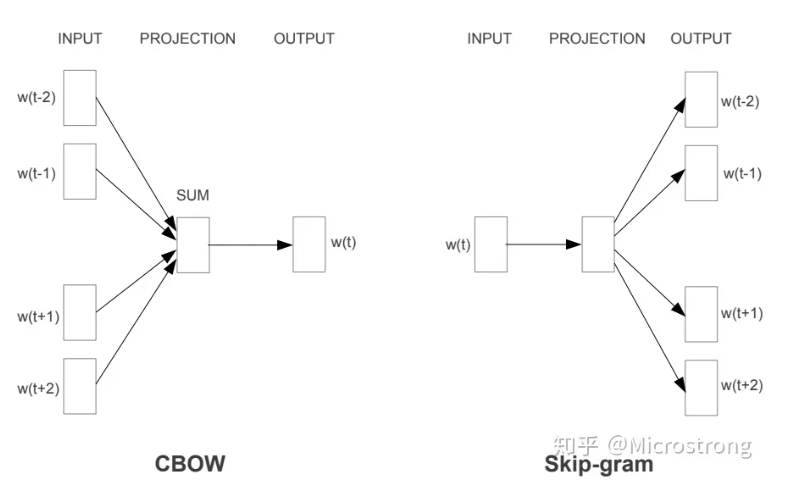
2.1 CBOW
2.1.1 Simple CBOW Model
为了更好的了解模型深处的原理,我们先从Simple CBOW model(仅输入一个词,输出一个词)框架说起。
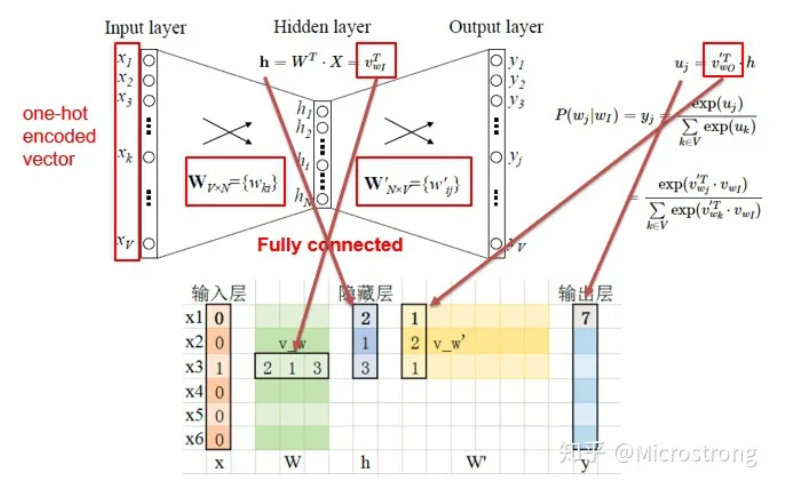
如上图所示:
- input layer输入的X是单词的one-hot representation(考虑一个词表V,里面的每一个词 x 都有一个编号i∈{1,…,|V|},那么词 x 的one-hot表示就是一个维度为|V|的向量,其中第i个元素值非零,其余元素全为0,例如: x2=[0,1,0,…,0]T );
- 输入层到隐藏层之间有一个权重矩阵W,隐藏层得到的值是由输入X乘上权重矩阵得到的(细心的人会发现,0-1向量乘上一个矩阵,就相当于选择了权重矩阵的某一行,如图:输入的向量X是[0,0,1,0,0,0],W的转置乘上X就相当于从矩阵中选择第3行[2,1,3]作为隐藏层的值);
- 隐藏层到输出层也有一个权重矩阵W’,因此,输出层向量y的每一个值,其实就是隐藏层的向量点乘权重向量W’的每一列,比如输出层的第一个数7,就是向量[2,1,3]和列向量[1,2,1]点乘之后的结果;
- 最终的输出需要经过softmax函数,将输出向量中的每一个元素归一化到0-1之间的概率,概率最大的,就是预测的词。
2.1.2 CBOW Multi-Word Context Model
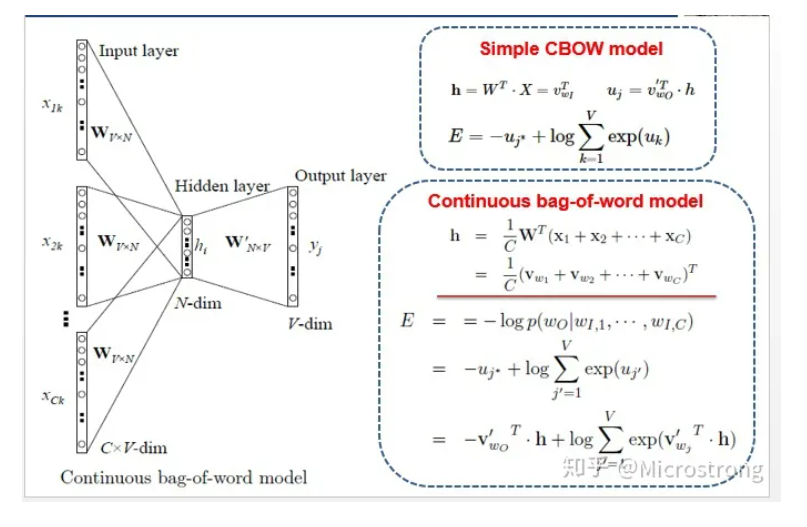
了解了Simple CBOW model之后,扩展到CBOW就很容易了,只是把单个输入换成多个输入罢了(划红线部分)。
h是求平均值后的结果。
2.2 Skip-gram
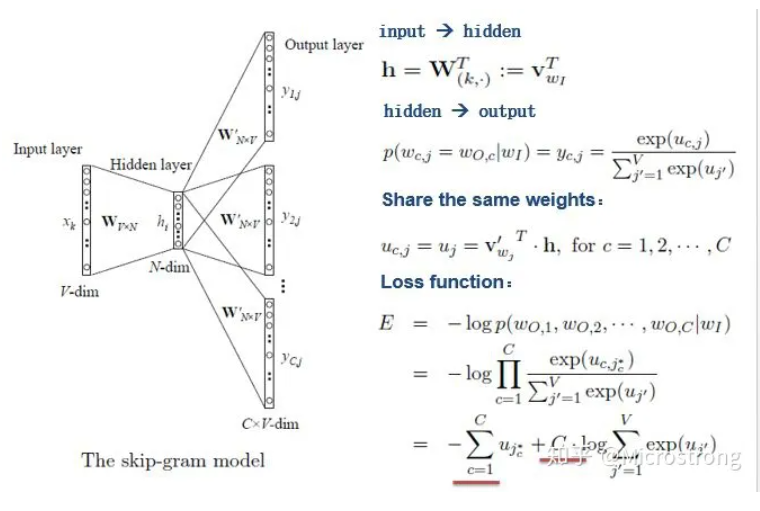
如上图所示,Skip-gram model是通过输入一个词去预测多个词的概率。输入层到隐藏层的原理和simple CBOW一样,不同的是隐藏层到输出层,损失函数变成了C个词损失函数的总和,权重矩阵W’还是共享的。