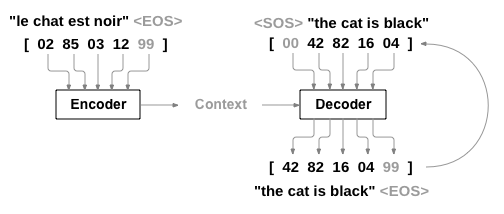
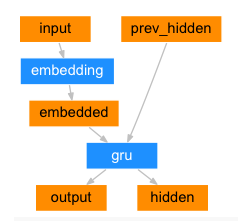
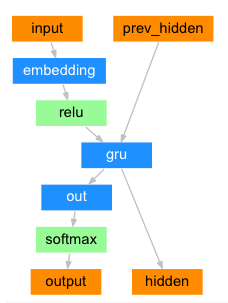
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderRNN, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
self.out = nn.Linear(hidden_size, output_size)
def forward(self, encoder_outputs, encoder_hidden, target_tensor=None):
batch_size = encoder_outputs.size(0)
decoder_input = torch.empty(batch_size, 1, dtype=torch.long, device=device).fill_(SOS_token)
decoder_hidden = encoder_hidden
decoder_outputs = []
for i in range(MAX_LENGTH):
decoder_output, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
decoder_outputs.append(decoder_output)
if target_tensor is not None:
decoder_input = target_tensor[:, i].unsqueeze(1)
else:
_, topi = decoder_output.topk(1)
decoder_input = topi.squeeze(-1).detach()
decoder_outputs = torch.cat(decoder_outputs, dim=1)
decoder_outputs = F.log_softmax(decoder_outputs, dim=-1)
return decoder_outputs, decoder_hidden, None
def forward_step(self, input, hidden):
output = self.embedding(input)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.out(output)
return output, hidden
|