attention介绍!💐
attention介绍
如果仅在编码器和解码器之间传递上下文向量,则该单个向量承担对整个句子进行编码的负担。注意力允许解码器网络“聚焦”在编码器输出的不同部分,用于解码器自身输出的每一步。
1.soft attention
**query:**解码器中对下一个预测目标作为输入的hidden值。
**key:**编码器的输出值。
具体为:
1 | |
注意力机制是将注意力上下文与decoder的输入值进行结合,加上前一个解码目标输出的隐藏值作为新的解码目标的输入。在解码器中具体应用在:
1 | |
因为是求一个解码目标的注意力上下文,所以该上下文一定是和前一个解码目标相关且有一个独立的权重来和编码内容进行加权。
因此注意力网络需要将query和key作为输入,产生权重值之后进行梯度优化。
Wa,Ua,Va的初始值也是随机的,在训练过程中不断进行梯度优化,得到合适的权重值。
tips:
为什么需要单独对query和key都进行注意力空间的映射?如果不映射的话,那么从key*Va这一部分的值就是固定的,无法获取好的特征。
2.self attention
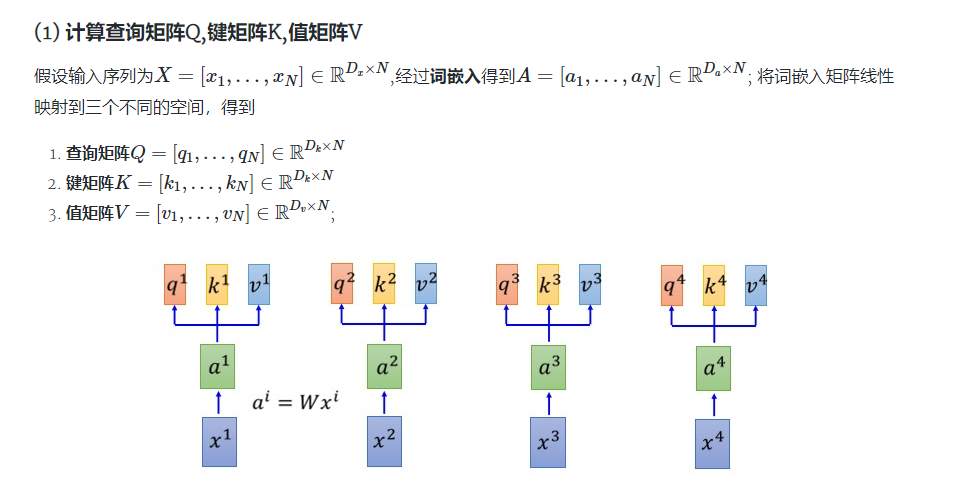
如图所示,每一个输入值都会映射到三个空间Q,K,V
Q的作用:和soft attention中的query一样,用作指定解码目标的参数,在自注意力机制中,因为每一个解码目标的特异性参数是自己本身,所以需要一个Q的映射。
K的作用:和soft attention中的key一样,用来获取每一个词对自身的影响。
V的作用:和soft attention中求加权值时和权重相乘的值一样,只不过在soft attention中值是原来的encoder_output,而在自注意力机制中中需要多映射到一个值空间中去。
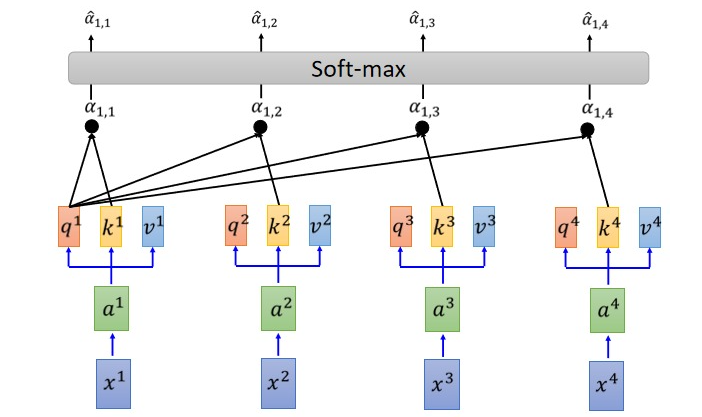
具体流程:
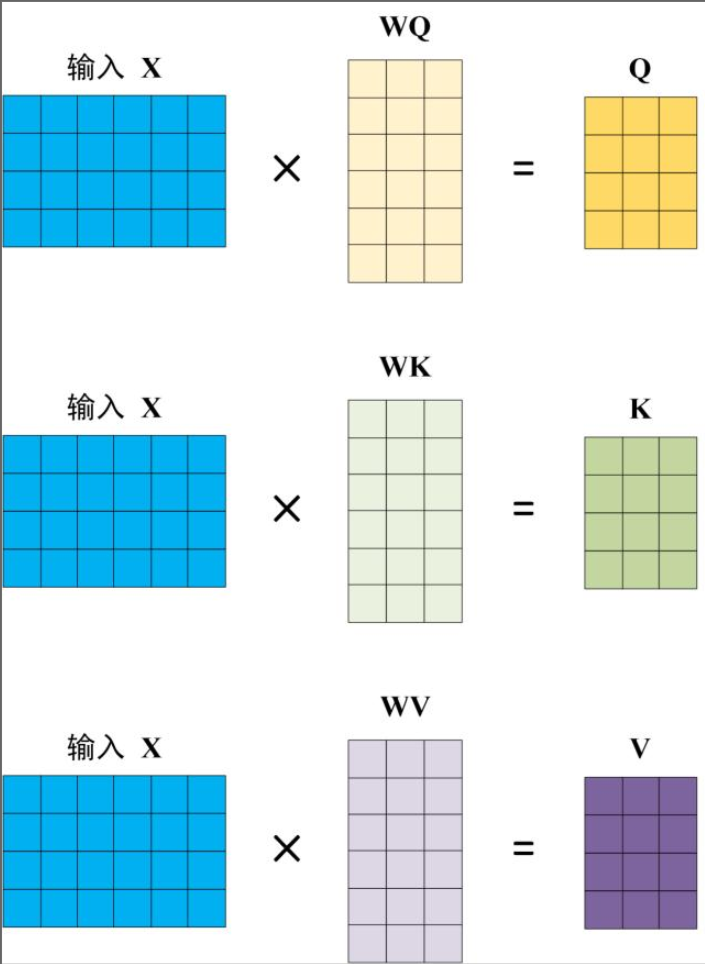
2.1 Q, K, V 的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
2.2 Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:

公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以 dk 的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q乘以KT ,1234 表示的是句子中的单词。
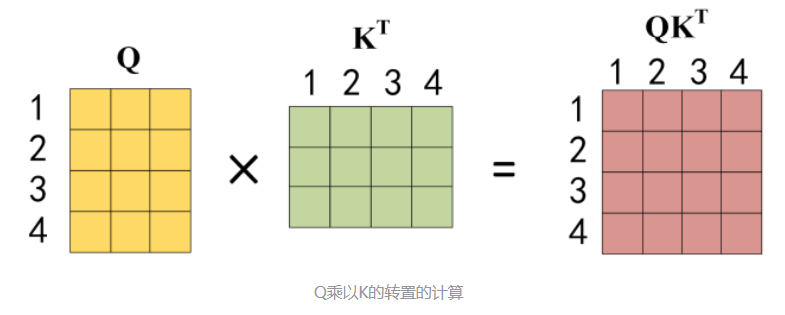
得到QKT 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1.
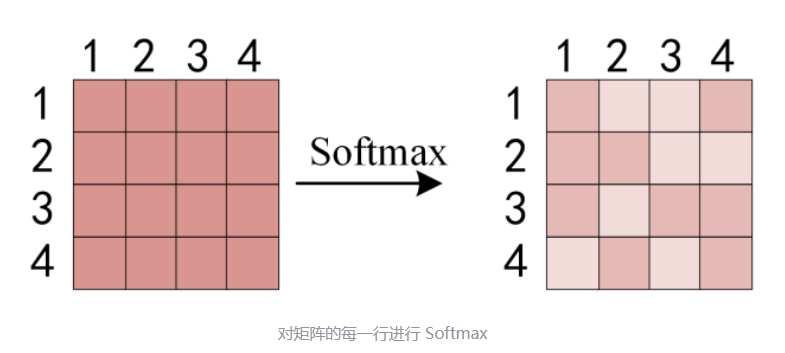
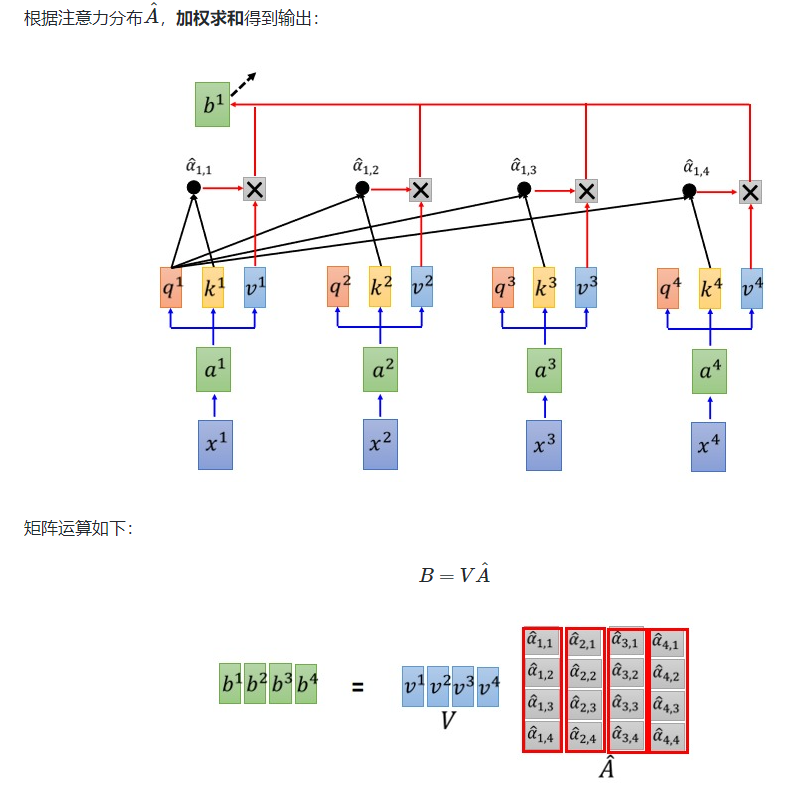
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z。
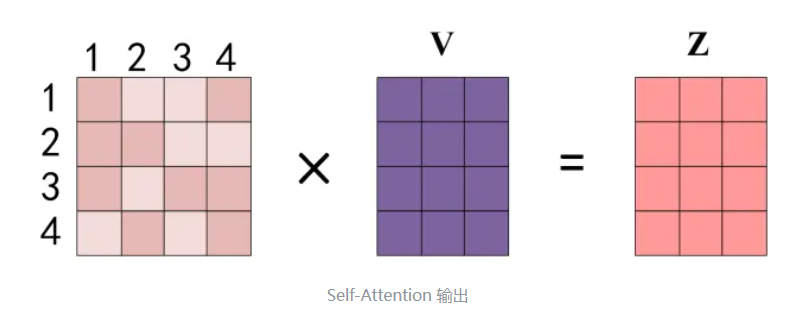
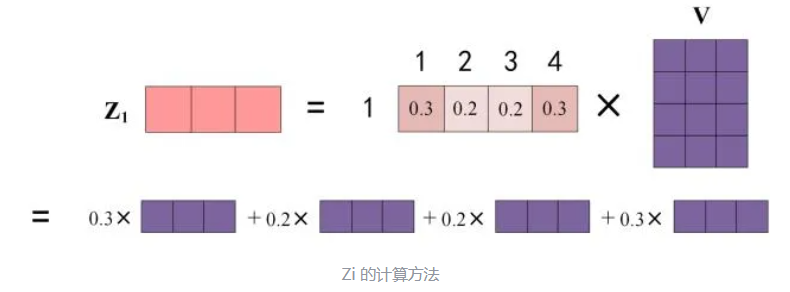
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 �1 等于所有单词 i 的值 �� 根据 attention 系数的比例加在一起得到,如下图所示:
3.Multi-Head Attention
在上一步,我们已经知道怎么通过 Self-Attention 计算得到输出矩阵 Z,而 Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图。
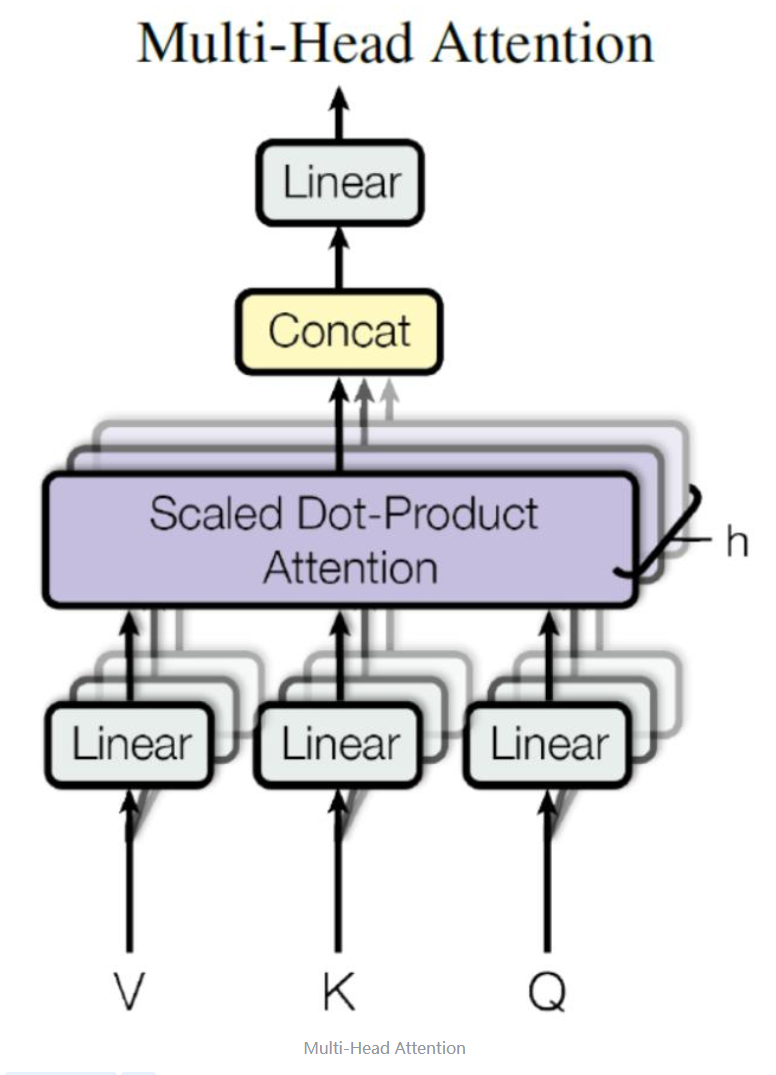
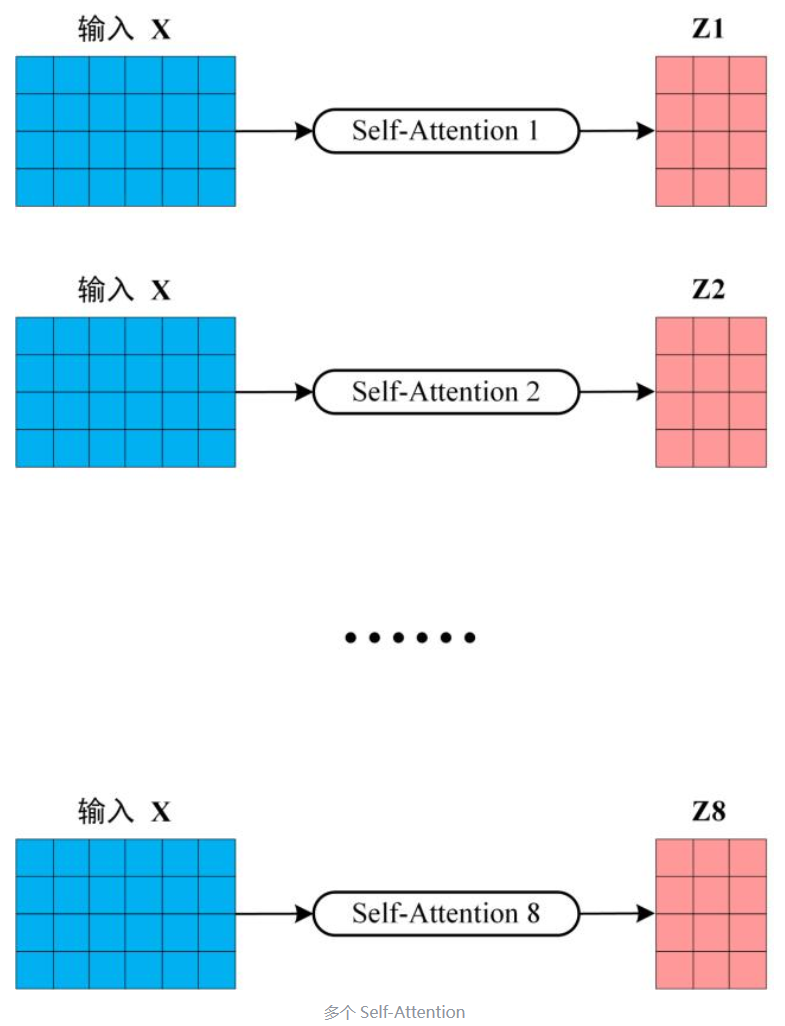
从上图可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。下图是 h=8 时候的情况,此时会得到 8 个输出矩阵Z。
得到 8 个输出矩阵 Z1 到 Z8 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
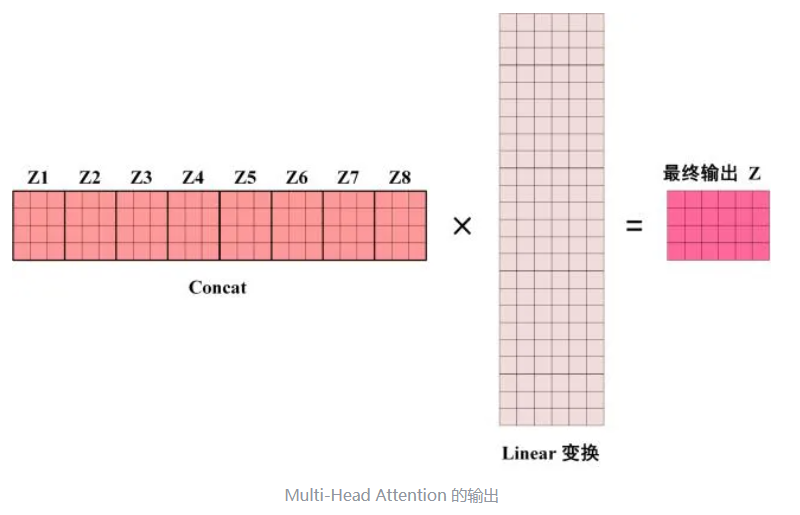
可以看到 Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的。