pytorch中nn模块!🍧
pytorch中nn模块
0.nn.Module
0.1 register_buffer
register_buffer 是 PyTorch 中 Module 类的方法之一,用于向模型注册持久性缓冲区。持久性缓冲区是一种特殊的张量,其数值在训练过程中不会更新,但会被保存到模型的状态字典中(state_dict),从而可以被保存和加载。
具体语法为:
1 | |
其中:
name:缓冲区的名称,用于在模型中标识缓冲区。tensor:要注册为缓冲区的张量。
以下是一个示例:
1 | |
输出结果为:
1 | |
可以看到,在模型中注册了一个名称为 'my_buffer' 的缓冲区,并且初始值为全零张量。注册的缓冲区会出现在模型的状态字典中,因此在保存和加载模型时会被自动处理。
register_buffer 方法通常用于将模型中需要持久存储的固定参数(如平均值、标准差等)注册为缓冲区。
1.nn.LogSoftmax
在PyTorch中,nn.LogSoftmax是一个用于计算对数softmax的模块。softmax函数用于将一个向量变换成概率分布,而log softmax函数则是在softmax的基础上取对数。log softmax函数的输出通常用作神经网络输出层的激活函数,特别是在多类别分类任务中。
nn.LogSoftmax模块的输入是一个张量,通常是网络的原始输出(未经softmax处理),输出是一个张量,其中包含对数softmax的结果。
下面是一个简单的示例,演示如何使用nn.LogSoftmax模块:
1 | |
在这个示例中,我们首先创建了一个具有随机值的原始输出张量 raw_output。然后,我们创建了一个 LogSoftmax 模块,并在 dim=1 的维度上对原始输出进行了对数softmax计算。最后,我们打印了对数softmax的结果 log_probs。
需要注意的是,对数softmax的输出是经过对数处理的概率分布,因此它的每个元素都是一个负数。通常在训练分类模型时,将对数softmax的输出与标签进行比较,计算损失函数,例如交叉熵损失。
tips:
取对数有几个好处:
- 数值稳定性:在计算概率时,通常会涉及到多个小概率的相乘,这可能会导致数值下溢(即结果接近于零)。通过取对数,可以将相乘转换为相加,避免了数值下溢的问题。同时,取对数也可以减少数值溢出的风险,特别是在计算指数时。
- 简化计算:取对数可以将复杂的指数运算转换为加法运算,从而简化了计算过程。这在机器学习和深度学习中尤为重要,因为许多优化算法(如梯度下降)都涉及到对数似然或对数损失的计算。
- 解释性:在某些情况下,对数可以提供更直观和易解释的结果。例如,在对数尺度下,乘法操作变成了加法操作,这使得数据的变化更容易理解。
- 统计性质:在统计学中,对数变换可以使数据更符合正态分布或者更接近线性关系,从而使得一些统计分析更加有效。
总的来说,取对数可以提高数值稳定性,简化计算,并在某些情况下提供更好的解释和统计性质,因此在实际应用中经常被使用。
2.nn.NLLLoss
nn.NLLLoss 是PyTorch中的一个损失函数,用于多分类问题中的负对数似然损失(Negative Log Likelihood Loss)。在PyTorch中,通常与LogSoftmax层结合使用,用于训练一个分类器,该分类器的输出是经过LogSoftmax处理的原始输出。
具体来说,nn.NLLLoss 期望输入是经过LogSoftmax处理后的对数概率分布的张量。它的计算方式是根据目标标签和模型预测的对数概率分布来计算损失值,然后返回平均损失值。
以下是 nn.NLLLoss 的一些主要参数和实现细节:
- 参数:
weight:可选参数,可以指定一个张量作为损失函数的权重,用于在某些类别上放大或减小损失。ignore_index:可选参数,指定一个类别索引,忽略该索引对应的预测值和目标值,不计入损失计算中。reduction:可选参数,指定损失的计算方式,可选值有'none'(不进行降维,返回每个样本的损失值)、'mean'(对所有样本的损失值取平均)、'sum'(对所有样本的损失值求和)。
1 | |
其中,output 是经过LogSoftmax处理后的模型输出的张量,target 是对应的目标标签的张量。output 的形状一般是 (batch_size, num_classes),target 的形状一般是 (batch_size),其中 batch_size 是一个批次的样本数量,num_classes 是分类的类别数量。
nn.NLLLoss 会将 output 中的每个样本的对数概率与 target 中对应样本的标签进行比较,并计算损失值。然后根据指定的 reduction 参数来进行降维操作,得到一个标量损失值,即最终的损失结果。
这个损失函数在训练分类器时非常常用,特别是在多分类问题中。
tips:
batch_size 是一个批次的样本数量。每个元素表示对应样本的类别标签,通常是一个整数值,表示样本属于哪个类别。例如,如果一个批次有 32 个样本,每个样本的类别标签分别为 [0, 1, 2, ..., 9],那么 target 的形状将是 (32,)。
3.nn.Dropout
在 PyTorch 中,nn.Dropout 是一个用于实现 dropout 操作的模块。Dropout 是一种在神经网络中用于防止过拟合的正则化技术。其原理是在训练过程中,随机将神经元的输出设置为零,从而减少神经元之间的依赖性,以防止过拟合。
nn.Dropout 模块在每次前向传播时以一定的概率(通常是0.5)将输入张量中的一些元素设置为零。这样做可以模拟在训练期间随机丢弃神经元的效果,从而使得网络更加健壮。
以下是一个简单的示例,展示了如何在 PyTorch 中使用 nn.Dropout:
1 | |
4.nn.GRU
nn.GRU 是 PyTorch 深度学习框架中的一个模块,用于实现门控循环单元(Gated Recurrent Unit,GRU)的神经网络层。GRU 是一种循环神经网络(Recurrent Neural Network,RNN)的变体,用于处理序列数据,例如文本、时间序列等。
GRU 与传统的 RNN 不同之处在于其引入了门控机制,有助于缓解长期依赖问题,并且具有较少的参数,训练更快。在 GRU 中,有两个门控单元:更新门(Update Gate)和重置门(Reset Gate)。这些门控单元有助于网络决定在每个时间步应该保留多少过去的信息,并决定在当前时间步应该考虑多少新的信息。这种机制有助于 GRU 更好地捕获序列中的长期依赖关系。
在 PyTorch 中,nn.GRU 模块实现了这种 GRU 结构,并提供了一个方便的接口,使用户能够轻松地在自己的模型中使用 GRU 层。通常,你可以通过实例化 nn.GRU 类来创建一个 GRU 层,并将其用作神经网络模型的一部分,用于处理序列数据的建模任务。
举例:
1 | |
输出:
1 | |
输入的词的个数为5,则output的第一个维度也为5,因为gru输出的是每个词的output。
5.nn.Embedding
nn.Embedding 是 PyTorch 中的一个类,用于创建一个可训练的词嵌入层。在自然语言处理任务中,词嵌入是将单词映射到高维实数向量的技术,它可以将单词表示为连续的向量空间中的点,从而捕捉单词之间的语义相似性和关系。
nn.Embedding 接受两个参数:
num_embeddings:表示词汇表的大小,即词汇表中唯一单词的数量。embedding_dim:表示词嵌入的维度,即每个单词将被映射到的向量的维度。
在创建 nn.Embedding 实例时,PyTorch 会随机初始化词嵌入矩阵,大小为 (num_embeddings, embedding_dim)。在训练过程中,模型会通过反向传播自动学习这些词嵌入参数,以最小化损失函数。
nn.Embedding 的输入是一个整数张量,其中的每个整数代表词汇表中的一个单词的索引。它的输出是根据输入索引对应的词嵌入向量。这使得模型能够在训练过程中动态地学习单词的分布式表示,从而更好地理解语义和上下文信息。
以下是一个简单的示例,说明如何使用 nn.Embedding:
1 | |
这会输出每个索引对应的词嵌入向量。注意,输出的形状为 (5, 5),其中 5 是输入索引序列的长度,而 5 是词嵌入的维度。
tips:
在 PyTorch 中,nn.Embedding 是一个用于实现词嵌入(Word Embedding)的模块,用于将整数索引映射到密集向量表示。这些向量通常被用作神经网络的输入。
nn.Embedding 模块的参数是可以被学习的,这意味着它们在模型训练的过程中会被优化器所更新。具体来说,nn.Embedding 的参数是每个词嵌入向量的初始值,它们在训练过程中会根据模型的损失函数进行调整以提高模型的性能。
nn.Embedding 和 Word2Vec 都是用于表示词嵌入(Word Embedding)的技术,但它们有一些关键的区别:
- 实现方式:
nn.Embedding是 PyTorch 中的一个模块,用于将整数索引映射到密集向量表示。它是作为神经网络的一部分,在模型中被优化器所更新。- Word2Vec 是一种基于神经网络的词嵌入模型,它由两种不同的架构组成:Skip-gram 和 CBOW(Continuous Bag of Words)。这些模型通过在大规模文本语料库上进行训练,学习将词语表示为密集向量。
- 训练方式:
nn.Embedding的参数是在模型的训练过程中与其他神经网络参数一起优化的,通常作为整个神经网络的一部分。- Word2Vec 是通过在大规模文本语料库上进行训练来学习词嵌入。Skip-gram 模型通过预测上下文词语来学习词嵌入,而 CBOW 模型则通过预测目标词语来学习。
- 上下文考虑:
nn.Embedding并不考虑词语的上下文信息,它只是简单地将每个词语映射到一个固定长度的向量。- Word2Vec 考虑了词语的上下文信息,通过在训练过程中利用上下文词语来学习词嵌入。
- 适用场景:
nn.Embedding通常作为神经网络的一部分,用于在文本分类、语言建模等任务中学习端到端的表示。- Word2Vec 可以独立训练并用于生成词嵌入,然后可以在各种自然语言处理任务中使用这些预训练的词嵌入。
6.nn.CrossEntropyLoss
nn.CrossEntropyLoss 是PyTorch中的一个损失函数,用于多分类任务。CrossEntropyLoss 计算了模型的输出与目标标签之间的交叉熵损失。在神经网络的训练过程中,通过最小化交叉熵损失,可以使得模型的输出尽可能接近于真实的标签,从而提高模型的分类性能。
交叉熵损失的计算公式如下:
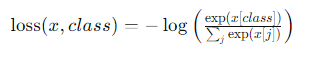
其中,x 是模型的原始输出(也称为 logits),class 是正确的类别标签,j 是所有类别的索引。
在 PyTorch 中,nn.CrossEntropyLoss 会自动将 logits 传入 softmax 函数,然后计算交叉熵损失。此外,它还可以处理标签的软性编码(one-hot 编码)或整数形式的标签。
简而言之,nn.CrossEntropyLoss 可以帮助我们定义一个目标函数,通过最小化该函数,我们的模型可以更好地适应多分类任务。
tips:
在使用nn.CrossEntropyLoss时,通过设置ignore_index参数为特定的类别索引,可以实现忽略该类别的效果。
1 | |