使用字符级RNN对名称进行分类 1.准备数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from io import open import globimport osdef findFiles (path ): return glob.glob(path)print (findFiles('data/names/*.txt' ))import unicodedataimport string" .,;'" len (all_letters)def unicodeToAscii (s ):return '' .join(for c in unicodedata.normalize('NFD' , s)if unicodedata.category(c) != 'Mn' and c in all_lettersprint (unicodeToAscii('Ślusàrski' ))def readLines (filename ):open (filename, encoding='utf-8' ).read().strip().split('\n' )return [unicodeToAscii(line) for line in lines]for filename in findFiles('data/names/*.txt' ):0 ]len (all_categories)
tips:
2.将名称转换为张量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import torchdef letterToIndex (letter ):return all_letters.find(letter)def letterToTensor (letter ):1 , n_letters)0 ][letterToIndex(letter)] = 1 return tensordef lineToTensor (line ):len (line), 1 , n_letters)for li, letter in enumerate (line):0 ][letterToIndex(letter)] = 1 return tensorprint (letterToTensor('J' ))print (lineToTensor('Jones' ).size())
tips:
这一步构建了两个方法,letterToTensor将单个字符转换为了一个二维张量,lineToTensor将一个单词转换为了三维张量,其中torch.zeros(len(line), 1, n_letters)中的1是因为 PyTorch 假设一切都是批量的 - 我们在这里只使用批处理大小 1。
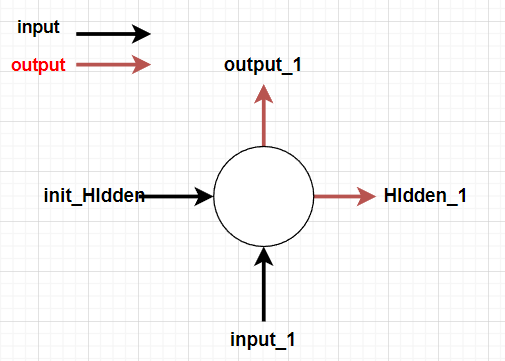
3.创建网络 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import torch.nn as nnclass RNN (nn.Module):def __init__ (self, input_size, hidden_size, output_size ):super (RNN, self).__init__()1 )def forward (self, input , hidden ):input , hidden), 1 )return output, hiddendef initHidden (self ):return torch.zeros(1 , self.hidden_size)128
tips:
该网络首先将输入层和隐藏层结合,然后通过线性层输出一个1*128的隐藏层,再将该层通过一个线性层转换为输出层,经过激活函数后输出。
为了运行这个网络的一个步骤,我们需要传递一个输入(在我们的例子中,是当前字母的张量)和一个之前的隐藏状态(我们首先将其初始化为零)。我们将返回输出(每种语言的概率)和下一个隐藏状态(我们保留该状态以备下一步使用)。
1 2 3 4 input = letterToTensor('A' )1 , n_hidden)input , hidden)
为了提高效率,我们不想为每一步都创建一个新的 Tensor,所以我们将使用 lineToTensor slices 而不是 letterToTensor slices。这可以通过预先计算 Tensor 的批次来进一步优化。
1 2 3 4 5 input = lineToTensor('Albert' )1 , n_hidden)input [0 ], hidden)print (output)
4.训练 在开始训练之前,我们应该做一些辅助功能。首先是解释网络的输出,我们知道这是每个类别的可能性。我们可以用来 Tensor.topk 获取最大值的索引:
1 2 3 4 5 6 def categoryFromOutput (output ):1 )0 ].item()return all_categories[category_i], category_iprint (categoryFromOutput(output))
tips:
topk返回值和索引。
我们还想要一种快速获取训练示例(名称及其语言)的方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import randomdef randomChoice (l ):return l[random.randint(0 , len (l) - 1 )]def randomTrainingExample ():return category, line, category_tensor, line_tensorfor i in range (10 ):print ('category =' , category, '/ line =' , line)
对于损失函数 nn.NLLLoss 是合适的,因为 RNN 的最后一层是 nn.LogSoftmax 。
1 criterion = nn.NLLLoss()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 learning_rate = 0.005 def train (category_tensor, line_tensor ):for i in range (line_tensor.size()[0 ]):for p in rnn.parameters():return output, loss.item()
tips:
rnn.zero_grad():在每个训练步骤之前清零模型参数的梯度。
p.data.add_(p.grad.data, alpha=-learning_rate):这行代码是针对循环神经网络(RNN)模型中的参数进行梯度下降更新的一种常见方式。
for p in rnn.parameters()::这个循环遍历了RNN模型中的所有参数。在PyTorch中,通过 parameters() 方法可以获取模型中所有需要进行学习的参数。
p.data.add_(p.grad.data, alpha=-learning_rate):这行代码是对每个参数进行更新的核心部分。让我们分解它:
p.data:表示参数 p 的数据值。p.grad.data:表示参数 p 的梯度值。alpha=-learning_rate:表示更新的步长,即学习率的负数。
实际上,这行代码执行了以下操作:
首先,它获取了参数 p 的数据值 p.data。
然后,它将参数的梯度值 p.grad.data 乘以学习率的负数 -learning_rate。
最后,它将这个乘以后的梯度值添加到参数的数据值中,实现了参数的更新。
这个过程基本上是梯度下降法的一步,其中学习率 learning_rate 控制着参数更新的步长。通常,这行代码会在优化器(如随机梯度下降优化器或Adam优化器)中的参数更新步骤中被使用。
值得注意的是,这种方式在更新参数时直接修改了参数的数据值,而没有通过优化器对象来处理。因此,在使用这种方式时需要手动设置学习率、考虑动量等优化技巧。一般情况下,更推荐使用PyTorch提供的优化器,例如 torch.optim.SGD 或 torch.optim.Adam,这些优化器会自动管理参数更新的细节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import timeimport math100000 5000 1000 0 def timeSince (since ):60 )60 return '%dm %ds' % (m, s)for iter in range (1 , n_iters + 1 ):if iter % print_every == 0 :'✓' if guess == category else '✗ (%s)' % categoryprint ('%d %d%% (%s) %.4f %s / %s %s' % (iter , iter / n_iters * 100 , timeSince(start), loss, line, guess, correct))if iter % plot_every == 0 :0