rust基础知识!🐖
rust基础知识
1.Cargo
Cargo 是 Rust 的构建系统和包管理器。Rust 开发者常用 Cargo 来管理 Rust 工程和获取工程所依赖的库。
Cargo 除了创建工程以外还具备构建(build)工程、运行(run)工程等一系列功能,构建和运行分别对应以下命令:
1 | |
2.输出到命令行
Rust 输出文字的方式主要有两种:println!() 和 print!()。这两个”函数”都是向命令行输出字符串的方法,区别仅在于前者会在输出的最后附加输出一个换行符。当用这两个”函数”输出信息的时候,第一个参数是格式字符串,后面是一串可变参数,对应着格式字符串中的”占位符”,这一点与 C 语言中的 printf 函数很相似。但是,Rust 中格式字符串中的占位符不是 “% + 字母” 的形式,而是一对 {}。
1 | |
如果我想把 a 输出两遍:
1 | |
在 {}之间可以放一个数字,它将把之后的可变参数当作一个数组来访问,下标从 0 开始。
如果要输出 { 或 } 怎么办呢?格式字符串中通过 分别转义代表 { 和 }。但是其他常用转义字符与 C 语言里的转义字符一样,都是反斜杠开头的形式。
3.变量
Rust 是强类型语言,但具有自动判断变量类型的能力。这很容易让人与弱类型语言产生混淆。
如果要声明变量,需要使用 let 关键字。例如:
1 | |
在这句声明语句之后,以下三行代码都是被禁止的:
1 | |
- 第一行的错误在于当声明 a 是 123 以后,a 就被确定为整型数字,不能把字符串类型的值赋给它。
- 第二行的错误在于自动转换数字精度有损失,Rust 语言不允许精度有损失的自动数据类型转换。
- 第三行的错误在于 a 不是个可变变量。
前两种错误很容易理解,但第三个是什么意思?难道 a 不是个变量吗?
这就牵扯到了 Rust 语言为了高并发安全而做的设计:在语言层面尽量少的让变量的值可以改变。所以 a 的值不可变。但这**不意味着 a 不是”变量”**(英文中的 variable),官方文档称 a 这种变量为”不可变变量”。
如果我们编写的程序的一部分在假设值永远不会改变的情况下运行,而我们代码的另一部分在改变该值,那么代码的第一部分可能就不会按照设计的意图去运转。由于这种原因造成的错误很难在事后找到。这是 Rust 语言设计这种机制的原因。
当然,使变量变得”可变”(mutable)只需一个 mut 关键字。
1 | |
常量与不可变变量的区别
既然不可变变量是不可变的,那不就是常量吗?为什么叫变量?
变量和常量还是有区别的。在 Rust 中,以下程序是合法的:
1 | |
但是如果 a 是常量就不合法:
1 | |
变量的值可以”重新绑定”,但在”重新绑定”以前不能私自被改变,这样可以确保在每一次”绑定”之后的区域里编译器可以充分的推理程序逻辑。 虽然 Rust 有自动判断类型的功能,但有些情况下声明类型更加方便:
1 | |
这里声明了 a 为无符号 64 位整型变量,如果没有声明类型,a 将自动被判断为有符号 32 位整型变量,这对于 a 的取值范围有很大的影响。
重影
重影的概念与其他面向对象语言里的”重写”(Override)或”重载”(Overload)是不一样的。重影就是刚才讲述的所谓”重新绑定”,之所以加引号就是为了在没有介绍这个概念的时候代替一下概念。
重影就是指变量的名称可以被重新使用的机制:
1 | |
这段程序的运行结果:
1 | |
重影与可变变量的赋值不是一个概念,重影是指用同一个名字重新代表另一个变量实体,其类型、可变属性和值都可以变化。但可变变量赋值仅能发生值的变化。
1 | |
这段程序会出错:不能给字符串变量赋整型值。
4.数据类型
Rust 语言中的基础数据类型有以下几种。
4.1 整数型(Integer)
整数型简称整型,按照比特位长度和有无符号分为以下种类:
| 位长度 | 有符号 | 无符号 |
|---|---|---|
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
isize 和 usize 两种整数类型是用来衡量数据大小的,它们的位长度取决于所运行的目标平台,如果是 32 位架构的处理器将使用 32 位位长度整型。
整数的表述方法有以下几种:
| 进制 | 例 |
|---|---|
| 十进制 | 98_222 |
| 十六进制 | 0xff |
| 八进制 | 0o77 |
| 二进制 | 0b1111_0000 |
| 字节(只能表示 u8 型) | b’A’ |
很显然,有的整数中间存在一个下划线,这种设计可以让人们在输入一个很大的数字时更容易判断数字的值大概是多少。
4.2 浮点数型(Floating-Point)
Rust 与其它语言一样支持 32 位浮点数(f32)和 64 位浮点数(f64)。默认情况下,64.0 将表示 64 位浮点数,因为现代计算机处理器对两种浮点数计算的速度几乎相同,但 64 位浮点数精度更高。
1 | |
4.3 数学运算
用一段程序反映数学运算:
1 | |
许多运算符号之后加上 = 号是自运算的意思,例如:
sum += 1 等同于 sum = sum + 1。
注意:Rust 不支持 ++ 和 **–**,因为这两个运算符出现在变量的前后会影响代码可读性,减弱了开发者对变量改变的意识能力。
4.4 布尔型
布尔型用 bool 表示,值只能为 true 或 false。
4.5 字符型
字符型用 char 表示。
Rust的 char 类型大小为 4 个字节,代表 Unicode标量值,这意味着它可以支持中文,日文和韩文字符等非英文字符甚至表情符号和零宽度空格在 Rust 中都是有效的 char 值。
Unicode 值的范围从 U+0000 到 U+D7FF 和 U+E000 到 U+10FFFF (包括两端)。 但是,”字符”这个概念并不存在于 Unicode 中,因此您对”字符”是什么的直觉可能与Rust中的字符概念不匹配。所以一般推荐使用字符串储存 UTF-8 文字(非英文字符尽可能地出现在字符串中)。
注意:由于中文文字编码有两种(GBK 和 UTF-8),所以编程中使用中文字符串有可能导致乱码的出现,这是因为源程序与命令行的文字编码不一致,所以在 Rust 中字符串和字符都必须使用 UTF-8 编码,否则编译器会报错。
4.6 复合类型
元组是用一对 ( ) 包括的一组数据,可以包含不同种类的数据:
1 | |
数组用一对 [ ] 包括的同类型数据。
1 | |
5.注释
Rust 中的注释方式与其它语言(C、Java)一样,支持两种注释方式:
1 | |
5.1 用于说明文档的注释
在 Rust 中使用 // 可以使其之后到第一个换行符的内容变成注释。
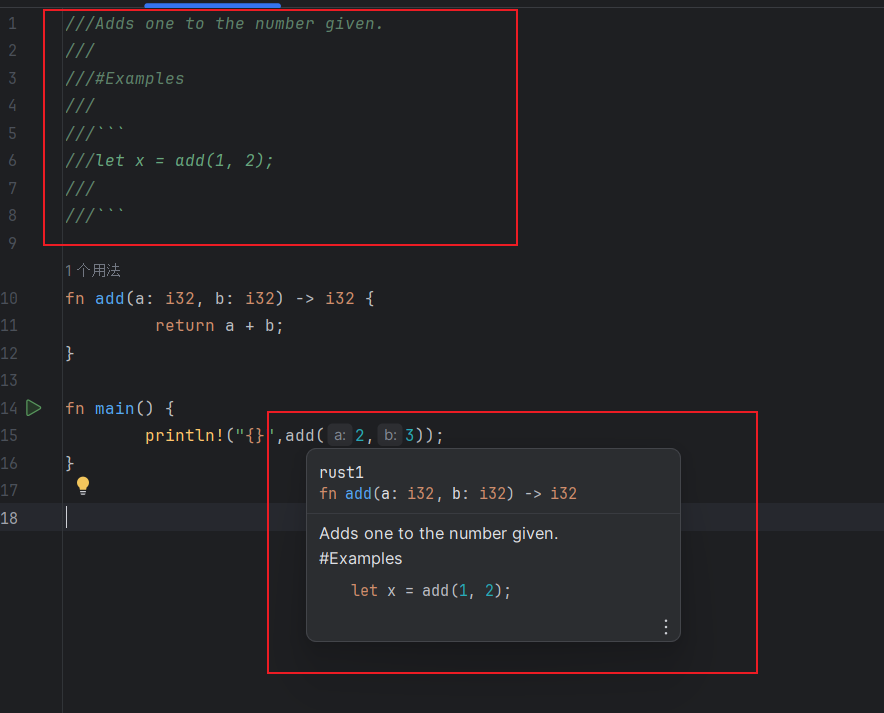
在这种规则下,三个正斜杠 /// 依然是合法的注释开始。所以 Rust 可以用 /// 作为说明文档注释的开头:
1 | |
程序中的函数 add 就会拥有一段优雅的注释,并可以显示:
6.函数
函数在 Rust 语言中是普遍存在的。
通过之前的章节已经可以了解到 Rust 函数的基本形式:
1 | |
其中 Rust 函数名称的命名风格是小写字母以下划线分割:
1 | |
运行结果:
1 | |
注意,我们在源代码中的 main 函数之后定义了another_function。 Rust不在乎您在何处定义函数,只需在某个地方定义它们即可。
6.1 函数参数
Rust 中定义函数如果需要具备参数必须声明参数名称和类型:
1 | |
运行结果:
1 | |
6.2 函数体的语句和表达式
Rust 函数体由一系列可以以表达式(Expression)结尾的语句(Statement)组成。到目前为止,我们仅见到了没有以表达式结尾的函数,但已经将表达式用作语句的一部分。
语句是执行某些操作且没有返回值的步骤。例如:
1 | |
这个步骤没有返回值,所以以下语句不正确:
1 | |
表达式有计算步骤且有返回值。以下是表达式(假设出现的标识符已经被定义):
1 | |
Rust 中可以在一个用 {} 包括的块里编写一个较为复杂的表达式:
1 | |
运行结果:
1 | |
很显然,这段程序中包含了一个表达式块:
1 | |
而且在块中可以使用函数语句,最后一个步骤是表达式,此表达式的结果值是整个表达式块所代表的值。这种表达式块叫做函数体表达式。
注意:x + 1 之后没有分号,否则它将变成一条语句!
这种表达式块是一个合法的函数体。而且在 Rust 中,函数定义可以嵌套:
1 | |
6.3 函数返回值
在上一个嵌套的例子中已经显示了 Rust 函数声明返回值类型的方式:在参数声明之后用 -> 来声明函数返回值的类型(不是 : )。
在函数体中,随时都可以以 return 关键字结束函数运行并返回一个类型合适的值。这也是最接近大多数开发者经验的做法:
1 | |
但是 Rust 不支持自动返回值类型判断!如果没有明确声明函数返回值的类型,函数将被认为是”纯过程”,不允许产生返回值,return 后面不能有返回值表达式。这样做的目的是为了让公开的函数能够形成可见的公报。
注意:函数体表达式并不能等同于函数体,它不能使用 return 关键字。
7.条件语句
在 Rust 语言中的条件语句是这种格式的:
1 | |
在上述程序中有条件 if 语句,这个语法在很多其它语言中很常见,但也有一些区别:首先,条件表达式 number < 5 不需要用小括号包括(注意,不需要不是不允许);但是 Rust 中的 if 不存在单语句不用加 {} 的规则,不允许使用一个语句代替一个块。尽管如此,Rust 还是支持传统 else-if 语法的:
1 | |
运行结果:
1 | |
Rust 中的条件表达式必须是 bool 类型,例如下面的程序是错误的:
1 | |
虽然 C/C++ 语言中的条件表达式用整数表示,非 0 即真,但这个规则在很多注重代码安全性的语言中是被禁止的。
结合之前章学习的函数体表达式我们加以联想:
1 | |
这种语法中的 { block 1 } 和 { block 2 } 可不可以是函数体表达式呢?
答案是肯定的!也就是说,在 Rust 中我们可以使用 if-else 结构实现类似于三元条件运算表达式 (A ? B : C) 的效果:
1 | |
运行结果:
1 | |
注意:两个函数体表达式的类型必须一样!且必须有一个 else 及其后的表达式块。
8.循环
8.1 while 循环
while 循环是最典型的条件语句循环:
1 | |
运行结果:
1 | |
Rust 语言到此教程编撰之日还没有 do-while 的用法,但是 do 被规定为保留字,也许以后的版本中会用到。
在 C 语言中 for 循环使用三元语句控制循环,但是 Rust 中没有这种用法,需要用 while 循环来代替:
1 | |
1 | |
8.2 for 循环
for 循环是最常用的循环结构,常用来遍历一个线性数据结构(比如数组)。for 循环遍历数组:
1 | |
运行结果:
1 | |
这个程序中的 for 循环完成了对数组 a 的遍历。a.iter() 代表 a 的迭代器(iterator),在学习有关于对象的章节以前不做赘述。
当然,for 循环其实是可以通过下标来访问数组的:
1 | |
运行结果:
1 | |
8.3 loop 循环
身经百战的开发者一定遇到过几次这样的情况:某个循环无法在开头和结尾判断是否继续进行循环,必须在循环体中间某处控制循环的进行。如果遇到这种情况,我们经常会在一个 while (true) 循环体里实现中途退出循环的操作。
Rust 语言有原生的无限循环结构 —— loop:
1 | |
运行结果:
1 | |
loop 循环可以通过 break 关键字类似于 return 一样使整个循环退出并给予外部一个返回值。这是一个十分巧妙的设计,因为 loop 这样的循环常被用来当作查找工具使用,如果找到了某个东西当然要将这个结果交出去:
1 | |
运行结果:
1 | |
9.所有权
计算机程序必须在运行时管理它们所使用的内存资源。大多数的编程语言都有管理内存的功能:C/C++ 这样的语言主要通过手动方式管理内存,开发者需要手动的申请和释放内存资源。但为了提高开发效率,只要不影响程序功能的实现,许多开发者没有及时释放内存的习惯。所以手动管理内存的方式常常造成资源浪费。
所有权对大多数开发者而言是一个新颖的概念,它是 Rust 语言为高效使用内存而设计的语法机制。所有权概念是为了让 Rust 在编译阶段更有效地分析内存资源的有用性以实现内存管理而诞生的概念。
9.1 所有权规则
所有权有以下三条规则:
- Rust 中的每个值都有一个变量,称为其所有者。
- 一次只能有一个所有者。
- 当所有者不在程序运行范围时,该值将被删除。
这三条规则是所有权概念的基础。
9.2 变量范围
我们用下面这段程序描述变量范围的概念:
1 | |
变量范围是变量的一个属性,其代表变量的可行域,默认从声明变量开始有效直到变量所在域结束。
我们把字符串样例程序用 C 语言等价编写:
1 | |
ust 之所以没有明示释放的步骤是因为在变量范围结束的时候,Rust 编译器自动添加了调用释放资源函数的步骤。
这种机制看似很简单了:它不过是帮助程序员在适当的地方添加了一个释放资源的函数调用而已。但这种简单的机制可以有效地解决一个史上最令程序员头疼的编程问题。
9.3 变量与数据交互的方式
变量与数据交互方式主要有移动(Move)和克隆(Clone)两种: